At server.camp, we were facing a quite disastrous situation yesterday, Oct 6th, 2025. Anyone trying to visit our website yesterday, was prevented from doing so by this frightening warning message.
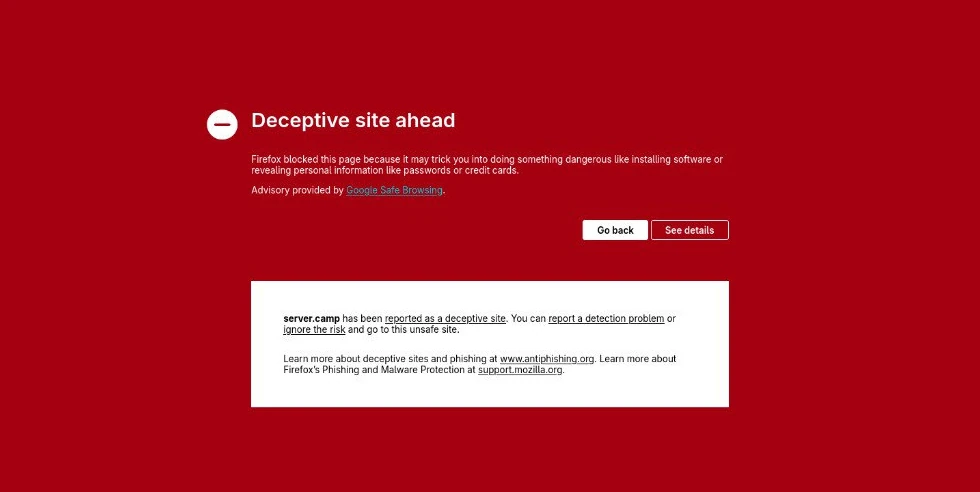
Allegedly, our homepage was a dangerous phishing site that Internet users should urgently avoid. All subdomains were affected as well, including status.server.camp and support.server.camp.
Some background
With its Safe Browsing API, Google operates a service that aims to make the internet safer and keep users away from malicious sites. Generally, this is important and makes a lot of sense. Google indexes sites that are classified as suspicious by any means, e.g. because they contain phishing links (SOCIAL_ENGINEERING) or malware (MALWARE) or may otherwise pose a threat (POTENTIALLY_HARMFUL_APPLICATION).
This data can then be accessed free of charge by anyone via the API. As the operator of a URL shortener (such as Anchr.io, shameless self-promo 🤫), for example, you could first query the API for each new link to verify its “legitimacy”. All major browsers – including Chrome, Firefox, and Safari, but not the independent Chromium project – also integrate Google Safe Browsing. As soon as a user attempts to access a page classified as unsafe in the browser, the message shown above appears.
Unfortunately, to the dismay of our visitors, this was also mistakenly the case for our pages yesterday. Even worse: LinkedIn apparently consumes the Safe Browsing API as well, which meant that the server.camp LinkedIn page was offline for a while, all our posts were automatically deleted and suddenly had zero followers.
Troubleshooting
After we got over the initial shock, we quickly began searching for the error’s root cause. It soon became clear that there was some connection to our mailcow. In simple terms, mailcow is an open-source email server stack, which we use internally. In the issue tracker and community forum of mailcow, we came across recent reports from a lot of other users who were facing the same problem – their websites were also incorrectly declared as “deceptive sites.” Apparently, Google’s classification algorithm considers mailcow to be a phishing site, for reasons that are unclear.
- Google Safe Browsing flags mailcow pages as dangerous (#6747)
- Google Safe Browsing meldet mailcow Seiten als gefährlich (🇩🇪)
We were alone! We realized that it wasn’t our fault. It was a “structural” problem at Google. A bug that caused harmless websites to end up as false_positives in their index.
A workaround
We immediately set about implementing the measures and changes suggested in the forum and on GitHub and reported the error classification to Google. After that, all we could do was wait then. Apparently, it can take up to several days for such a report to be processed and for the change to be fully propagated across the Internet.
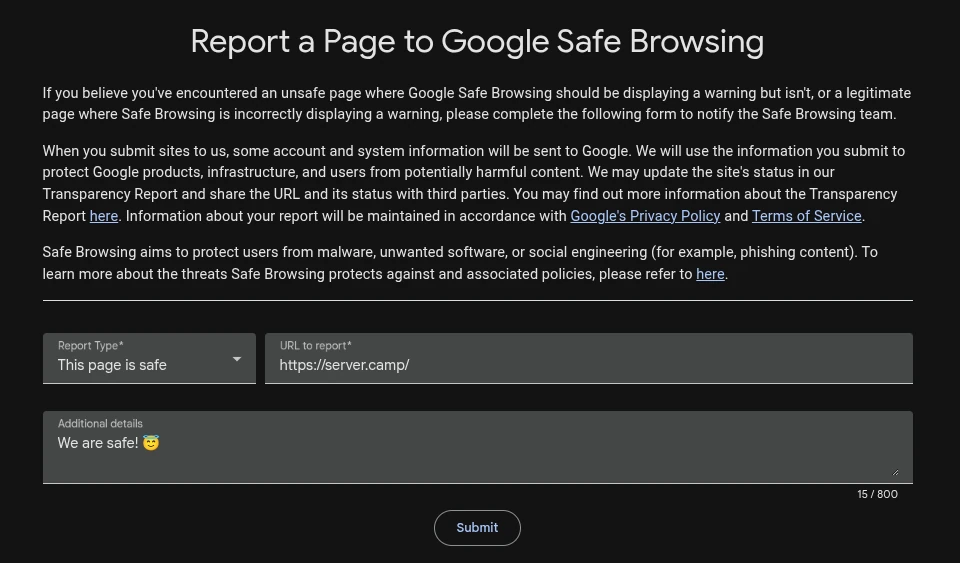
The workaround appears to have been effective. However, the underlying issue with Google remains, meaning that “innocent” website operators continue to run the risk of being adversely affected by the flawed classification algorithm.
We have been back online since the early hours of October 7th. However, the trust we have lost with our users cannot be restored with a few clicks and some goodwill from Google… 😔.
Conclusion
This incident gave us firsthand experience of just how great Google’s responsibility is, but also how powerful they are. Due to their enormous reach, a simple, automated misclassification has the potential to “accidentally” ruin small businesses and startups just like that. Once again, it became clear to us that today’s internet is less decentralized and independent of “single points of failure” than one might think (and than it should be).
Note: Because I’m lazy, large parts of this article are auto-translated from the German blog post I wrote this morning for our company website.
Comments