
(Dublin City Marathon 2016, Source)
.jpg){kind=link}
Introduction
This summer I attended a run in my home town, where each of the 6,000 runners was assigned a certain bib number to wear on their shirt for time tracking. During the run, several photographers took pictures of each runner, which were made available online afterward. To find oneself among tens of thousands of pictures, the web portal offered an option to search by one’s bib number. However, the images are tagged manually by volunteer users, so only a very small fraction of all photos was actually searchable by number.
I wondered if this might not be a perfectly suitable task for machine learning-based image processing and so I took it as a challenge to build a system that automatically tags pictures with the bib numbers they contain.
Problem Statement
Given high-resolution RGB images like the above, which contain one to N persons, each of them wearing 0 to 1 numbers at the front of their bodies, I want to output each of these numbers in text form and associate them to the picture. I figured the numbers to be between 1 and 5 digits long.
Before starting, I conducted some research and found that, surprisingly, the problem seems to be less trivial than it seemed. First, classical OCR methods didn’t seem to work at all, even if the image is precisely cropped only to the number. Second, while one-digit recognition with machine learning is trivial (MNIST, etc.), multi-digit is a much harder problem. Usually, it can’t just be solved as a simple classification, because there are not 10 possible output classes anymore, but several thousand. Some other solution was required.
Approach
Multi-Digit Recognition
As a starting point, I discovered a paper called “Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks”, which presents a multi-digit classifier for house numbers – using convolutional neural nets – that was trained on Stanford’s SVHN dataset. Recognizing house numbers is a quite similar problem to recognizing bib numbers, so I decided to take this approach as a basis.
Luckily, I found an open-source PyTorch implementation of the neural net on GitHub. I needed to do several tweaks and change some code to make it fit my needs, but it was a good start.
Eventually, I hoped that I could take the pre-trained SVHN model and use transfer-learning to fit it to my problem.
However, before I could get started with the actual classification, there was another problem to solve. The input for the digit classifier is, as one could expect, not a high-res image with a lot of noise and distraction in it, but rather only a very precise excerpt from that image, that exactly contains one single number and not much more.
Object Detection for Localization
I needed to find a way to localize the 2D-coordinates of all number signs within a picture. To solve that, I decided to utilize TensorFlow’s object detection framework, whose purpose is exactly that; recognizing certain objects in an image and outputting a 2-dimensional bounding box for it.
Outline
In summary, I planned to build a two-step classification system.

Step 1: Recognize bib numbers and crop them out
Step 2: Use first step’s output as input for a fine-tuned SVHN classifier
Data Preparation
Data Acquisition and Labeling for Step 1
First, I started collecting 1,000 images from the web portal mentioned above. I manually labeled them for step 1 by drawing bounding boxes around each number, using labelImg and wrote a short script to separate them into training, test and validation sets.
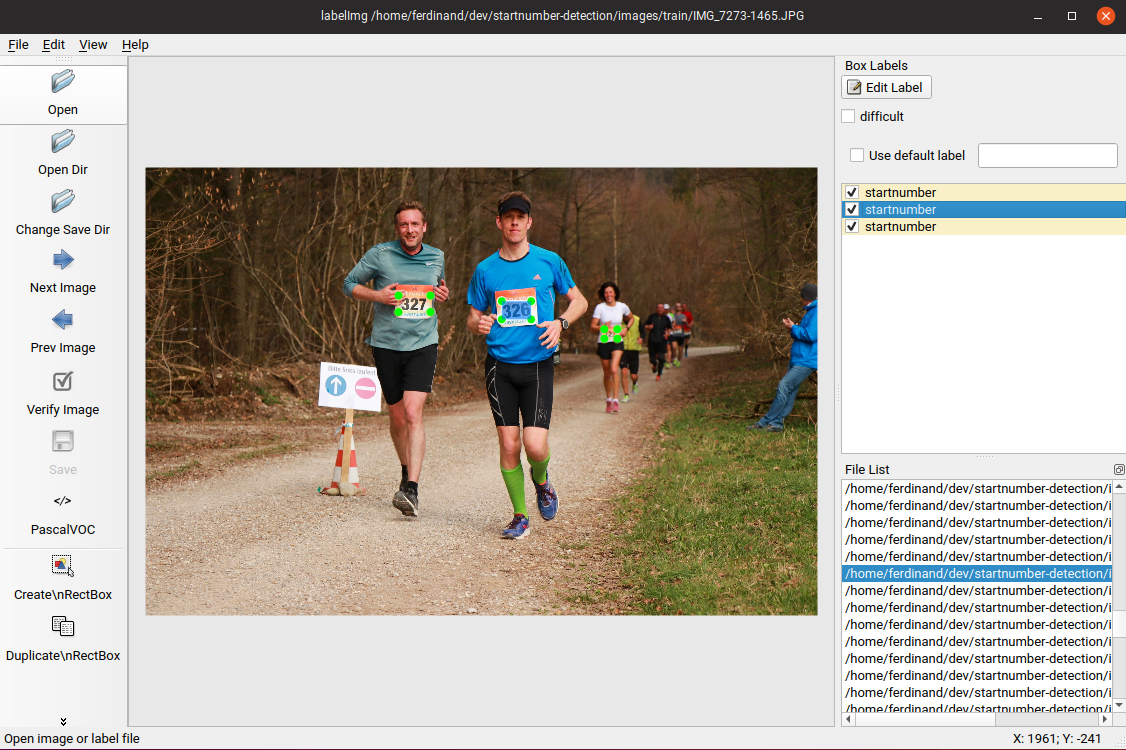
The output of this step is an XML file for every image, containing information about the respective labels and their bounding boxes. Using a script called generate_tfrecord.py, those XML files can be combined together with their corresponding images into one big TFRecord file for each set (training, test, validation), that is the format required as input for TensorFlow object detection.
Training the Object Detector
For training the object detection model to recognize bib numbers, I decided not to train it completely from scratch, but fine-tune the pre-trained ssd_mobilenet_v1_pets set to my needs. The TensorFlow object detection framework provides a quite convenient way to do so by simply adjusting a few config files. If you’re interested in more details about training a custom object detector, there’s a very interesting article on pythonprogramming.net on this.
After training for ~ 100,000 episodes, I ended up with a model – represented as a so-called frozen_inference_graph.pb binary file - that was able to find bib number signs in sports imagery.
Letting the model run on my data yields quite reliable results of bounding boxes of bib numbers, which I could then use to crop the original images to smaller ones with another small script.

Labeling for Step 2
To produce training data for the second step – digit recognition – I needed to do another round of labeling. This time, the little cropped images of numbers had to be assigned their actual numbers in text form. I did this manually and using a simple CSV table.
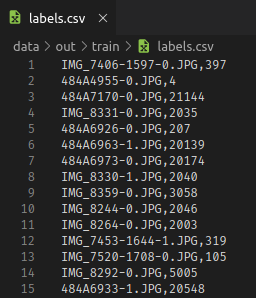
Adding Data Augmentation
To (1.) overcome my lack of training data and (2.) hopefully make the model generalize better, I considered it a good idea to introduce some image augmentation. I extended the given DataLoader in a way that a specified fraction of the number of raw training images is artificially added to the data set in a slightly transformed form. To be more precise, I used PyTorch’s TorchVision Transforms to introduce (a) color jitter (variance in brightness, contrast, saturation, and hue), (b) affine transformations and (c) rotation.
Another thing I changed from the original implementation is the way input images are transformed. The net’s 64 x 64 x 3 input layer expects square RGB images. However, obviously, barely any of the training images are actually square. Whereas the original implementation essentially squeezes or tugs the images to match the required dimensions, I considered this unfavorable, especially for wide numbers, e.g. 5-digit numbers. Instead, I changed the input transformation in a way, that images are “thumbnailed”.
However, so far I didn’t evaluate which way of pre-processing yields better performance.

Fine-Tuning using Transfer Learning
Eventually, after all data massaging and pre-processing was done, I could start with the interesting part: the actual digit recognition.
Due to my lack of large amounts of high-variance, representative training data, I decided that it might not be a good idea to train the CNN model-based classifier completely from scratch. Instead, I used a pre-trained model (trained on SVHN dataset) with an accuracy of 95 % for house numbers as a feature extractor and fine-tune it to work with bib numbers. To do so, I conveniently used the given train.py script. However, in my understanding, it does not train only the net’s very last classification layer while keeping all previous convolutional- and normalization layers frozen, but re-trains every layer. This is not exactly what I wanted, but it turned out to work quite well.
Results
After training for 72,000 episodes with a batch size of 256, a learning rate of 10^-3 and an augmentation factor of 1.5, I eventually evaluated my two-step classification system on a set of 120 test images and reached an accuracy of ~ 76 %. That is, about 3/4 of all numbers among all images were detected and classified correctly.
However, there is still room for improvements. First, using a lot more training data would probably boost accuracy. Second, I didn’t do any hyper-parameter tuning, which would probably also improve performance by a few percentage points.
Comments